ANSWERS TO EXERCISES
1.1.
As a string of characters:
'Joe\'s Pizza is "cute"'
or 'Joe\'s Pizza is \"cute"'
or 'Joe\'s Pizza is "cute\"'
or 'Joe\'s Pizza is \"cute\"'
As a compound symbol:
"Joe's Pizza is \"cute\""
or "Joe\'s Pizza is \"cute\""
1.2.
'-'16 0
1.3.
(a) e.1 s.X s.X
; (b) e.1 t.X e.2 t.X e.3
; (c) t.1 e.2
or
e.1 t.2
.
1.4.
(a) t.X
becomes b
; (b) failure; (c) e.6
becomes
A(B)
, e.4
becomes C D
; (d) failure.
1.5.
Add {
(e.X) '0' = e.X;
(e.X) e.Y's'= <Add (e.X) e.Y>'s'; }
1.6.
Addb {
(e.X'0')(e.Y s.1) = <Addb (e.X)(e.Y)> s.1;
(e.X'1')(e.Y'0') = <Addb (e.X)(e.Y)>'1';
(e.X'1')(e.Y'1') =
<Addb (<Addb (e.X)('1')>)(e.Y)>'0';
(e.X)(e.Y) = e.X e.Y; }
2.1.
$ENTRY Go { = <Job> }
Job { = <Prout 'Please enter a line'>
<Job1 <Card>>; }
Job1 {
0 = <Prout 'Good-bye!'>;
e.X = <Prout 'The translation is:'>
<Prout <Trans-line e.X>>
<Job>; }
2.2.
(a) Sum-1 and 'Sum-1 '
(b) Sum'-'1 and 'Sum -1 '
(c) as above
(d) (9'+'25)'()' and '(9 +25 )\(\)'
2.3.
* Conv-xx, conversion of a file typed for Input
* into a file for Xxin.
* Call: refgo conv-xx+reflib file-name
$ENTRY Go { =
<Xxout (<Arg 1>) <Input <Arg 1>>>; }
$EXTERN Input,Xxout;
2.4.
Merge { s.1 s.2 =
<Implode <Explode s.1> <Explode s.2>>; }
2.5.
(a)
7 6 8 5 4 9 3 2 10 11 1
e.A( t.2) ( Sunday ) ( s.Day s.Night )
The variable e.A
(No.7) is closed.
(b)
1 3 2 4 5 7 9 8 10 6 11
( e.Word ) e.1( ( e.Word ) e.Transl ) e.2
No.3 is closed, No.4 open, No.9 repeated, No.11 closed.
(c)
1 8 9 10 7 6 2 11 12 13 4 5 3
( e.1'+' e.2'+' e.3) e.1 '+' e.2 ( e.3)
No.5 is closed, No.6 repeated, No.8 open, No.10 closed,
Nos.11 and 13 repeated.
2.6.
(a) ('di' 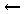 e.A)('f' t.1)('ident' e.B)
(b) ( e.1)('d' s.X)('iffi' e.2) ('ent' e.3)
(c) Failure
(d) ( e.1)( e.2)(A B C e.3)
(e) (A(A B) e.1)((C) eX)(D e.2)
e.A)('f' t.1)('ident' e.B)
(b) ( e.1)('d' s.X)('iffi' e.2) ('ent' e.3)
(c) Failure
(d) ( e.1)( e.2)(A B C e.3)
(e) (A(A B) e.1)((C) eX)(D e.2)
3.1.
The second delete sign will show up in the answer:
#Crocodile
To send the message, insert the sentence:
()'#'e.2 = <Prout 'Extra delete signs!'>
<Prout '#'e.2>;
between sentences 2 and 3.
3.2.
Cut {
(e.1)(e.2) = <Cut1 (()e.1) (()e.2)>; }
Cut1 {
((e.R1) t.X e.1) ((e.R2) t.X e.2) =
<Prout (e.R1 t.X)(e.R2 t.X)>
<Cut1 (()e.1) (()e.2)>;
((e.R1) t.X e.1) ((e.R2) t.Y e.2) =
<Cut1 ((e.R1 t.X) e.1) ((e.R2 t.Y) e.2)>;
e.Z = ; }
3.3.
Equal {
(s.X e.1) (s.X e.2) = <Equal (e.1) (e.2)>;
((e.T1)e.1) ((e.T2)e.2) =
<Equal1 <Equal (e.T1)(e.T2)> (e.1)(e.2)>;
() () = T;
(e.1) (e.2) = F; }
Equal1 {
T e.A = <Equal e.A>;
F e.A = F; }
3.4.
F {
s.X e.1 = <F1 s.X()e.1>;
= <Prout 'No repeated symbols'>; }
F1 {
s.X(e.2)s.X e.1 = s.X e.2 s.X;
s.X(e.2)s.Y e.1 = <F1 s.X(e.2 s.Y) e.1>;
s.X(e.2) = <F e.2>; }
3.5.
With implicit recursion:
Isect {
(s.X e.1)(e.2 s.X e.3) = s.X <Isect (e.1)(e.2 e.3)>;
(s.X e.1)(e.2) = <Isect (e.1)(e.2)>;
()(e.2) = ; }
Without implicit recursions:
Isect {
(s.X e.1) e.I (s.X e.2) = s.X <Isect (e.1)(e.I e.2)>;
(s.X e.1) e.I (s.Y e.2) =
<Isect (s.X e.1) e.I s.Y (e.2)>;
(s.X e.1) e.I () = <Isect (e.1) (e.I)>;
() e.I (e.2) = ; }
NOTE:
We have used the ``closed'' format of Isect
which provides the space for one more expression,
originally empty.
If the format were <Isect (e.1)e.2>
, we would have to
introduce an auxiliary function.
3.6.
2c + t
, where t = 1 if one string is a prefix of the other.
With this definition:
* Precedence-conservative
* <Prec e.C(e.1)(e.2)> == T(e.1)(e.2)
* == F(e.1)(e.2)
* where e.C is the common part of e.1 and e.2.
Prec {
e.C ()(e.2) = T(e.C)(e.C e.2);
e.C (e.1)() = F(e.C e.1)(e.C);
e.C (t.1 e.X)(t.1 e.Y) = <Prec e.C t.1 (e.X)(e.Y)>;
e.C (t.1 e.X)(t.2 e.Y) =
<Addc e.C <Pre-term t.1 t.2>(t.1 e.X)(t.2 e.Y)>;}
Addc { e.C s.T(e.X)(e.Y) = sT.(e.C e.X)(e.C e.Y); }
the time is c + t.
3.7.
String {
e.1 s.2 = <String e.1> s.2;
= T;
e.1(e.2) = F e.1(e.2); }
Pal { e.X = <Pal1 ()e.X()>; }
Pal1 {
(e.L) s.1 e.2 s.1 (e.R) =
<Pal1 (e.L s.1) e.2 (s.1 e.R)>;
(e.L)(e.R) = T e.L e.R;
(e.L) e.I (e.R) = F e.L e.I e.R; }
3.8.
Fact {s.N = <Loop F(1) I(1) N(s.N)>; }
Loop {
F(s.F) I(s.N) N(s.N) = <* s.N s.F>;
F(s.F) I(s.I) N(s.N) =
<Loop F(<* s.I s.F>) I(<+ s.I 1>) N(s.N)>;
}
3.9.
* Recursive definition
Reverse {
s.1 e.2 = <Reverse e.2> s.1;
= ; }
*Iterative definition
Reversei { e.X = <Revit ()(e.X)>; }
Revit {
(e.R)(s.1 e.2) = <Revit (s.1 e.R)(e.2)>;
(e.R)() = e.R; }
3.10.
See function Pprout
in reflib
.
3.11.
* Multibracket Backtracking
Mback {
[e.1(e.2 ^e.3)e.4] = <Mback [e.1 ^(e.2 e.3)e.4]>;
[.e.1 ^e.2.] = e.1 e.2; };
This function achieves the result by moving
pointer back to the beginning of the expression.
The same can be done by moving the pointer forwards.
3.12.
(a)
* Call: <Tree [. ^s.X.]>
* where s.X is the root node.
Tree {
*1. A leaf. Jump over.
[e.1 ^s.X'.'e.2] = <Tree [e.1 s.X'.' ^e.2]>;
*2. A node with subtree. Enter it.
[e.1 ^s.X(e.T) e.2] = <Tree [e.1 s.X( ^e.T)e.2]>;
*3. A 'hanging' node. Generate subtree.
[e.1 ^s.X e.2] = <Tree [e.1 ^<Subtree s.X> e.2]>;
*4. Up the tree.
[e.1(e.2 ^)e.3] = <Tree [e.1(e.2) ^e.3]>;
*5. End of work
[.e.1 ^.] = e.1; }
(b) All those nodes the processing of which has been completed
are in the left multibracket and in the format s.X(e.S)
,
where e.S
is the completed subtree for s.X
.
Those nodes the processing of which has been started
but not yet completed are also in the left multibracket,
but in the format
s.X)(
because the left parenthesis
following s.X
is represented by an inverted pair of parentheses.
Therefore, we modify setnence 3 above as:
*3. A 'hanging' node. See whether repeated.
[e.1 ^s.X e.2] = <Tree1
(<Rep s.X[. ^e.ML(e.1 ).]> )(s.X e.2)e.MR>;
The two new funcitons are defined as follows:
* See whether the subtree was already built
Rep {
*1. Repeated node found.
s.X [e.1 ^s.X(e.S) e.2] =
Yes(e.S) <Mback [e.1 ^s.X(e.S) e.2]>;
*2. A different symbol.
s.X [e.1 ^s.Y e.2] = <Rep s.X [e.1 s.Y ^e.2]>;
*3. Enter a parenthesis
s.X [e.1 ^(e.2)e.3] = <Rep s.X [e.1( ^e.2)e.3]>;
*4. Exit a parethesis
s.X [e.1(e.2 ^)e.3] = <Rep s.X [e.1(e.2) ^e.3]>;
*5. End of work.
s.X [.e.1 ^.] = No e.1; }
Tree1 {
*1. Repeated node. Cope subtree.
(Yes(e.S)e.1)(s.X e.2)e.MR =
<Tree (e.1)(s.X(e.S) e.2)e.MR>;
*2. New node. Compute subtree.
(No e.1)(s.X e.2)e.MR =
<Tree (e.1)(<Subtree s.X> e.2)e.MR>;
}
4.1.
Addop {
e.1 s.Op e.2, '+-': e.X s.Op e.Y =
(e.1) s.Op e.2;
e.1 = <Prout 'No additive operations'>; }
4.2.
Less {
(e.1) e.2, <- e.1 e.2>: '-'e.Z = T;
(e.1) e.2 = F;
e.A = <Less <Format e.A>>; }
Lesseq {
(e.1) e.2, <- e.2 e.1>: '-'e.Z = F;
(e.1) e.2 = T;
e.A = <Lesseq <Format e.A>>; }
Format {
'-'s.1 e.2 = ('-'s.1) e.2;
'+'s.1 e.2 = (s.1) e.2;
s.1 '-'e.2 = (s.1) '-'e.2;
s.1 '+'e.2 = (s.1) e.2;
s.1 e.2 = (s.1) e.2; }
4.3.
S123 {
e.A 1 e.1, e.1:
{e.B 2 e.2, e.2:
{e.C 3 e.D = T;
e.C = F };
e.B = F };
e.A = F }
4.4.
Fa {
e.1 s.X s.Y e.2,
<Less s.Y s.X>: T,
<Less 100 <+ s.X s.Y>>: T = s.X s.Y;
e.1 = <Prout 'No such pair'>;
}
Fb {
e.1 s.X s.Y e.2, <Less s.Y s.X>: T,
<Less 100 <+ s.X s.Y>>:
{T = <Prout 'It is greater'>;
F = <Prout 'It is not greater'>;
};
e.1 = <Prout 'No such pair'>;
}
4.5.
* Dictionary is stored as DICT
$ENTRY Go { =
<Br 'dict='<Xxin 'DICT'>>
<Prout 'Type in additions'>
<Addition <Input>> ;
}
Addition {
= <Prout 'No additions. Go ahead.'>
<Job>;
e.X = <Prout 'OK. Go ahead.'>
<Xxout ('DICT') e.X<Cp 'dict'>>
<Br 'dict='eX<Dg 'dict'>>
<Job>;
}
$EXTRN Input,Xxout,Xxin;
... etc. as before
6.1.
Fun-n {
s.N e.A = <Mu <Implode 'Fun'<Symb s.N>> e.A>; }
6.2.
Insert between the third and the fourth sentences:
'*'e.1 = <Prout 'Error: no upgrade of 'e.1>;
6.3.
(a) '*'((Add) (35)16)
(b) '*'((Up) ('*V'((F) ('*VE'1)'*VE'2)) '*V!'('*E'3))
(c) <Comp 'A*B'>
(d) Impossible. This is equivalent to <Dn 'A*B'>
,
and no expression becomes active when downgraded. Compare
with Exercise 6.4(b).
6.4.
(a) 51
(b) 'A*B'
6.5.
Two functions must be modified:
Check-end {
= <Prout 'End of session'>;
'*'Error = <Job>;
e.X = <Out <Ev-met e.X>>; }
Out {
0 e.X = <Prout 'The result is:'>
<Prout <Up e.X>> <Prout> <Job>;
1 e.X = <Prout 'Result depends on unknowns'>
<Prout> <Job>;
2 e.X = <Prout 'Recognition impossible'>
<Prout 'View field in metacode:'>
<Pprout e.X> <Error e.X>;
}
$EXTRN Pprout,Error;